狼书
http 知识
请求响应模型
http.createServer创建一个 Server 实例,参数是requestListener函数,一般形式为function(req, res)
请求
1 | GET /a?b=1 |
req.method的值为 GET,req.url为/a?b=1
响应
res.writeHead的第一个参数为状态码,第二个参数为 HTTP Headers,没有指定的话,默认其为空对象,Content-Type是 HTTP 头部信息里比较特殊的一个,它是MIME多用于互联网邮件扩展
| 类型 | 后缀 | Content-Type | 游览器渲染 |
|---|---|---|---|
| 普通文本 | .txt | text/plain | 文本 |
| HTML | .html | text/html | 网页 |
| JSON | .json | application/json | JSON 文本 |
| Gif | .gif | image/gif/图片 |
res.end是最简单粗暴向游览器写入数据的方法,
res.write(chunk, encoding)res.end(data, [, callback]), 它完成了两项内容,分别是将参数data放到body中,以及向游览器发送body中的所有数据.
核心要点
EventEmiter主要负责事件监听和处理,异步处理结合事件驱动可以获得更好的性能和易用性.Stream将请求响应过程抽象成一个流并在内存中传递,便于进行大文件处理,能够提高扩展性.
Stream
Stream本身是一个抽象接口,Node.js 中有很多对象实现了这个接口,例如对 HTTP 服务器发起请求的 request 对象,以及 stdout(标准输出).
和 UNIX 类似,在 Node.js 中,流模块的基本操作符是.pipe,通过它可以直接将上一步的结果作为下一步的输入,
这是非常高效的做法,尤其适合 Gulp 等 I/O 密集型操作.
Stream在Node.js中继承自EventEmitter,并且有多种实现方式.
|Readable Stream| Writable Stream|
|-:|:-|
|Http response, on the client| Http response, on the client|
|Http response, on the server| Http response, on the server|
|fz read stream|fz read stream|
|zlib stream|zlib stream|
|crypto stream|crypto stream|
|TCP socket|TCP socket|
|child process stdout and stderr|child process stdin|
1 | const stream = require('stream') |
Node.js Stream有 5 中操作类型
- Readable 可读操作类型,可以产出数据,这些数据可以被传送到其他流中,只需要调用 pipe 方法即可
- Writable 可写操作类型,只能流进不能流出
- Duplex 可读可写操作类型
- Transform 转换类型,可以写入数据,然后读出结果
- classic 经典接口,现在不怎么使用
原理
Stream 的精髓是将上一个输出作为下一个输入,这和 Linux 里管道的功能是一样的,比如查杀所有 Node.js 进程的命令如下.
1 | ps -ef | grep node | awk '{print $2}' | xargs kill -9 |
以下命令的要点如下:
ps -ef: 查看活动进程grep node: 过滤并获得包含 node 在内的所有进程awk '{print $2}': 通过 awk 获得包含 node 在内的所有进程号xargs kill -9: 通过 xargs 反转进程号,并作为 kill -9 的参数
这就是典型的管道机制,将ps -ef的输出结果作为grep node的输入参数,达到一气呵成的结果
可以发现request对象和response对象其实都是继承自 Stream 的.
1 | //request |
http 连接中的request对象是可读流Stream.Readable,而response对象是完整的可读可写流Stream.Duplex
1 | const http = require('http') |
那么http.request又是如何实现的呢, _http_client.js中对外暴露的是ClientRequest, 而ClientRequest继承自OutgoingMessage
1 | util.inherits(ClientRequest, OutgoingMessage) |
OutgoingMessage 是继承自 Stream 的,所有 HTTP 过程都是 IncomingMessage 和 OutgoingMessage 的过程,其对应的就是请求和响应的过程.
文件操作
1 | var source = fs.readFileSync('/path/to/source', {encoding: 'uft8'}) |
等于
1 | // pipe自动调用了data, end等事件 |
Http 代理
请求和响应都是继承自 Stream 的,所以可以直接通过 pipe 方法进行组装.
1 | const http = require("http"); |
以上代码的执行要点如下:
- 变量
httpProxy是http.request()函数的返回值,是一个新的请求。 - 通过
req.pipe(httpProxy)操作,req 就拥有了新的 res,即 HTTP 代理请求的响应,也就是说最终返回的是 response. - HTTP 代理完成了一次完整的 HTTP 请求过程,响应交由 res 返回,于是原来的请求相当于透传了 HTTP 代理的请求和响应。
http.request方法的返回值是<http.ClientRequest>,该方法继承自 Outgoingmessage, 如此可以推导出如下关系。
1 | http.request => http.ClientRequest => OutgoingMessage => Stream |
EventEmitter
Node.js 中会使用事件驱动模型,事件是核心机制.EventEmitter 是 Node.js 里典型的基于观察者设计模式的实现类.
所有的 Stream 对象都是 EventEmitter 的实例.常见的事件有以下几类.
- data: 当有数据可读时触发.
- end: 没有更多的数据可读时触发.
- error: 接收和写入过程中发生错误时触发.
- finish: 所有数据已被写入底层系统时触发.
请求事件
请求事件有一个非常典型的例子,即保存请求向服务器传递过去的表单数据.这时可以用 req.on(‘data’, cb)
1 | const http = require('http') |
1 | curl -d "a=1" http://127.0.0.1:3002/echo |
响应事件
http.ServerResponse继承自EventEmitter,而不是Writable Stream.其支持的事件不多,包括 close,finish,error 等.HTTP 本身是无状态的,一次请求只需要响应一次,所以响应后请求就会被销毁.
1 | const http = require("http"); |
http.Server 事件
http.Server 类继承自 net.Server 类,除了支持 req 事件和 res 事件,还支持 Server 类事件,例如文档中常见的 checkContinue, checkExpectation, clientError, close, connect, connection, request, upgrade 等.request 事件是用来拦截经过服务器处理的所有请求响应信息的,如果想记录或拦截请求信息,可以采用如下方式.
1 | const http = require("http"); |
HTTP 模块源码
Node.js 源码中和 HTTP 相关的文件
1 | ❯ ls -a lib | grep http |
| 文件 | 内容 | 功能描述 |
|---|---|---|
| _http_common.js | 用户向服务器发送的消息 | 请求 |
| _http_outgoing.js | 服务器向用户发送的消息 | 响应 |
| _http_client.js | 客户端向服务器发送 incoming 消息 | 访问 HTTP 服务 |
| _http_server.js | 服务器端实现 | 提供 HTTP 服务 |
| http.js | 核心模块 | 对外暴露 API |
HTTPS
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)是以安全目标为 HTTP 通道.HTTPS 在网络传输过程中主要使用 SSL/TLS 进行加密
- SSL: Secure Socket Layer,安全套接字层,是位于可靠的面向连接的网络协议层和应用协议层之间的一种协议层.SSL 通过互相认证,使用数字签名确保完整性,使用加密确保私密性,以实现客户端和服务器端的通信安全.SSL 由两部分组成,分别是 SSL 记录协议和 SSL 握手协议
- TLS: Transport Layer Security, 安全传输层协议,用以保证两个应用程序之间的保密性和数据完整性.该协议由两部分组成,分别是 TLS 记录协议和 TLS 握手协议
生成证书
以 Let’s Encrypr 为例,在终端安装 acme.sh 脚本,完成以下步骤便获得了 cronjob 定时任务, 每天 0 点自动检测所有证书,所有的修改都限制在(~/.acme.sh/)中
1 | curl https://get.acme.sh | sh |
使用证书
1 | const https = require('https') |
HSTS
HTTP Strict Transport Security
强制客户端使用 HTTPS 与服务器创建连接
1 | const express = require('express') |
Nginx HTTPS 配置
首先保证 Nginx 的 HTTPS 配置正常,生成 Diffie-Hellman Group,基于 DH 的 SSL 握手,不同于 RSA 的 SSL 握手
1 | sudo openssl dhparam -out /etc/ssl/certs/dhparam.pem 2048 |
1 | $ vim /etc/nginx/sites-available/wzy.monster |
启用更安全的 SSL 协议及 Ciphers
1 | $ vim /etc/nginx/nginx.conf |
重定向非 HTTPS 请求
1 | $ vim /etc/nginx/sites-available/wzy.monster |
1 | nginx -s reload |
Proxy
可以使用
hiproxy
Koa
基础
parseurl
专门用来解析 URL 地址
1 | function createReq (url, originalUrl) { |
输出
1 | Url { |
| 名称 | 描述 | 对应的 Koa 获取方式 |
|---|---|---|
| protocol | 该协议部分为 http: | ctx.protocol |
| slashes | 用于判断是否使用//作为分隔符 | 无 |
| auth | 与授权有关,绝大部分时间不会用到 | 无 |
| host | 由 hostname 和 port 组成 | ctx.host |
| port | 服务器对应的端口号,默认 80 | 无 |
| hostname | 服务器对应的域名或 ip 地址 | ctx.hostname |
| hash | 字符串,URL 的锚部分,对应 location.hash | 无 |
| search | 搜索部分,可以有多个参数,参数与参数之间通过&分割 | ctx.search |
| query | 查询字符串 | ctx.query |
| pathname | 从域名的最后一个/开始到?为止,是文件名部分,文件民部分不是一个 URL 必须有的部分,如果省略该部分,则使用默认的文件名 | 无 |
| path | 由 pathname 和 search 组成 | ctx.path |
| href | 完整的 URL 上面能有的都包含 | ctx.href |
在 Koa 中对应如下
1 | const Koa = require('koa') |
1 | { |
像 hash,port 这样的字段在 ctx.request 中都没有体现,可以通过 parseurl 绑定到 ctx 上
HTTP 头部
HTTP 采用了请求响应模型,网络资源传输的内容包括 message-header 和 message-body 两部分,首先传输的是 message-header,即头部消息。在 RFC 2616 中,HTTP 头部消息通常被分为 4 个部分:general header,request header,response header,entity header
ctx.header获取全部头部信息ctx.get获取特定的头部信息
1 | get_cache_control: ctx.get('Cache-Control') |
还有其他不常见但有实际应用的
- charset: 用于获取字符集
- length: 用于获取 Content-Length 长度
- accepts: 表示客户端可以接受的媒体类型
- acceptsEncoding: 表示支持的压缩算法
- accpetsCharsets: 表示支持的字符集
- accpetsLanguages: 表示支持的语言
- is: 用于判断请求中的 Content-Type 值与预期是否一致
- type: 用于获取或设置 Content-Type 值
游览器并非完整的将内容保存在本地,Chrome 会将缓存的文件保存在一个名为 User Data 的文件夹下,服务器端会和客户端约定一个有效期。
首先,使用 cache-control 判断是否有缓存,如果有缓存且缓存没有过期,就直接读取缓存并呈现。如果缓存已过期,就检测 Etag 值。响应头中的 Etag 表示资源的版本,游览器在发送请求时会自动附带名为 If-None-Match 的请求头字段来询问 Web 服务器该资源版本是否仍然可用。如果服务器发现该资源的版本仍然是最新的,就返回 304 状态码指示游览器继续使用缓存呈现,否则要返回 200 状态码并向 Web 服务器发起请求,协商缓存流程
http 状态码
ctx.status = ctx.response.status
- 500 Internet Server Error
- Forbidden
- Not Found
- Not Modified
- OK
Cookie
Cookie 是在 HTTP 下,服务器或脚本维护客户工作站上存在的一种信息形式。无论何时,只要用户连接到服务器,Web 站点就可以访问 Cookie 信息。
服务器端向客户端发送 Cookie,客户端的游览器把 Cookie 保存起来,然后在每次请求游览器时将 Cookie 发送到服务器端,在 HTML 文档被发送之前,Web 服务器会通过传送 HTTP 包头中的 Set-Cookie 消息把一个 Cookie 发送到用户的游览器中。
1 | Set-Cookie: koa.sid=BypBuJromdMeagLH19TbFKh3nxvHoOah; path=/; expires=Wed, 24 Jan 2018 06:44:28 GMT; httponly |
- name=value: 在 Cookie 中可以用这种方式对内容赋值
- maxAge: 最大失效事件 ms
- signed: Cookie 值签名
- path: Cookie 影响到的路径。如果路径不能匹配,游览器就不发送这个 Cookie
- domain: Cookie 影响到的域名
- secure: 值为 true 时,表示 Cookie 在 HTTP 中是无效的,在 HTTPS 中才有效
- httpOnly: 微软对 Cookie 做的扩展,如果 Cookie 中设置了 httpOnly,则将无法通过程序读取到 Cookie 信息,这样可以防止 XSS 攻击产生。
- Expires: 缓存失效时间。
在 Node.js 中,Cookie 是通过 response.writeHead 被写入的,代码如下
1 | // 设置过期时间为1min |
使用 Koa 写入 Cookie
1 | ctx.cookies.set('name', 'koasj', { signed: true }) |
查看源码,Koa 和 Express 中都使用了 cookies 模块
1 | const Cookies = require('cookies') |
req.secure 的意思是采用安全协议,可以理解为 ctx.protocol 的值是 https。另外,app.keys 是用于让 Cookie 进行签名的
1 | app.keys = ['im a newer secret', 'i like turtle'] |
获取参数的三种不同方法
| 参数名称 | 描述 | Express 中的获取方法 | Koa 中的获取方法 | 依赖模块 |
|---|---|---|---|---|
| params | 具名参数,如/user/:id | req.params | ctx.params | Koa 需要依赖 koa-router,而 Express 中有内置路由,无需依赖 |
| query | 查询字符串 | req.query | ctx.query | 内置,无需依赖 |
| body | 请求体,带有 body 请求的 POST 类中的 body 内容 | req.body | ctx.request.body | Express 依赖 bodyparser 模块,Koa 依赖 koa-bodyparser 模块 |
获取具名参数 params
koa-router 内置了 ctx.params
1 | router.get('/:id', (ctx, next) => { |
解析请求体 body
在 HTTP 请求中, POST、PUT 和 PATCH 类的请求方法中包含请求体,需要要单独处理,在 Node.js 原生的 http 模块中,请求体要基于流的方式接收和解析。
body-praser 是一个 HTTP 请求体解析的中间件可用于解析 JSON, Raw, 文本, URL-encoded 等格式的请求体,也是 Express 框架中的请求体解析中间件。在 Koa 中, body-parser 对应的中间件是 koa-bodyparser,且 koa-bodyparser 的用法更简单。如果包含 key-value 的数据实在请求体里被提交给服务器的,koa-bodyparser 默认值是 undefined,只有通过 bodyparser 进行解析才能正常使用。
1 | const bodyparser = require('koa-bodyparser')() |
1 | router.post('/post', (ctx, netx) => { |
1 | curl -d "a=1" http://127.0.0.1:3000/post |
获取查询字符串 query
1 | // GET /search?q=tobi+ferret |
POST 请求也可以使用查询字符串 query
body 解析
模块依赖
| 模块 | 描述 |
|---|---|
| koa-bodyparser | Koa 中间件,及处理配置的类型 |
| co-body | 使用 co 封装,用于获取请求内的 body 内容,是 koa-bodyparser 的核心依赖模块,主要对 HTTP 里的 req 进行处理,如果想定制特殊功能,使用 co-body 模块是非常好的选择 |
| stream-utils,raw-body | 从请求中获取 raw body,是 co-body 的依赖模块 |
表单类型列表
在 HTTP 请求头里,有些 HTTP 动词会带有 message-body,比如 POST,PATCH,DELETE 等,针使用这些动词的请求,我们需根据不同的 Content-Type 来返回 body.常用的处理方式如表
| 表单提交类型 | Content-Type | 说明 |
|---|---|---|
| JSON 数据 | application/json, application/json-patch+json, application/vnd.api+json, application/csp-report | 使用 RESTful JSON API 接口设计 |
| form 表单 | application/x-www-form-urlencoded | 常见的表单交互方式 |
| text 文本 | text/plain | 不常用,特定场景会用 |
Koa 通过 ctx.body 向游览器写入响应,而 ctx 上用了 body 关键字,所以只能通过 ctx.request.body 来处理请求体.
常见的 POST
JSON 类型
koa-bodyparser 默认配置是启动 JSON 支持,所以只要在请求之前添加这个中间件就行
表单类型
通用表单处理 form-data
通用表单处理指的是 form-data,其主要依赖两个模块
1 | npm install --save koa-bodyparser // 解析body内容 |
在 app.js 中启用 bodyparser 的可用类型,这种情况下默认支持 form
1 | app.use(bodyparser({ |
koa-multer 是一个非常便于使用的文件上传模块,使用 koa-multer 可以解析 body 中的流,并将其保存成文件,使用方法如下。
1 | const multer = require('koa-multer') |
koa-multer 的用法非常简单,只需把 upload 内置的中间件挂载到路由上即可,这里使用 upload.any()方法,不限制表单字段
1 | router.post('/post/formdata', upload.any(), ctx => { |
koa-multer 不会处理 multipart/form-data 以外的任何表单。
普通表单 x-www-form-ulrlencoded
1 | router.post('/post', (ctx, next) => { |
文件上传
1 | const multer = require('koa-multer') |
- 将 multer 的上传目录配置为根部录下的 uploads 目录
- upload 变量上的函数有 array, singgle, fields 等, 这些函数均可用来处理文件上传
- multer 的原始做法是通过 ctx.req.files 来获取上传的文件,然后对 api 进行调整
1 | ❯ curl -F 'avatar=@"test.png"' -F 'a=1' -F 'b=2' http://127.0.0.1:3000/upload/ |
文本类型 text/plain
bodyparser 默认支持的是 form 和 JSON 两种格式的解析,当出现 Content-Type:”text/plain”的时候是无法进行处理的,所以这时候需要在 koa-bodyparser 中开启 text 支持
1 | app.use(bodyparser({ |
在 Postman 中,所选类型为 raw
HTTP 模块
| 模块名称 | 是否支持游览器 | 描述 |
|---|---|---|
| request | 否 | Node.js 里使用最广泛的模块之一 |
| superagent | 是 IE10 及以上版本,使用 IE9 需要打补丁 | Node.js 里最好用的模块,其 API 使用起来最便捷,而且为 supertest 的核心模块 |
| got | 否 | 极简模块,可以满足绝大部分场景需求 |
| node-fetch | 否,担忧对应的游览器版的 fetch,规范相同 | 尤其适合 API 请求,在 axios 之前,React 等都是使用 fetch 模块的 |
| axios | 是 | 同时支持游览器和 Node.js 的模块,和 fetch 一样尤其适合用 API 请求,目前在 Reach 和 Vue 中使用极其广泛 |
request
功能十分强大,还有 request-promise 支持 Promise
1 | $ npm i -S request |
superagent
superagent 是一个轻量级 Node.js 模块,可读性好,设计人性化,有大量插件,推荐!
superagent 也是著名的测速模块 supertest 的基础模块
1 | $ npm i -S superagent |
got
request 过于复杂,Sindre Sorhus 开发了这个更简单易用。
node-fetch
优雅,同时兼容 Node.js 和 Browser
1 | const fetch = require('node-fetch') |
axios
和 fetch 类似,主流
1 | const axios = require('axios') |
API 开发
koa.res.api
1 | npm i -S koa.res.api |
1 | var Koa = require('koa') |
1 | // 直接返回API接口 |
响应处理
因为 JS 为动态语言,常会抛出 Uncaught TypeError 类的异常,做响应处理是非常重要的内容
Loadsh
使用 Lodash 的_get 方法,根据路径获取值,如果获取的值是 undefined,则会赋予解析结果以默认值。
1 | const _ = require('loadsh') |
TypeScript
tsc.ts --strictNullChecks 启用新的严格空值检查模式
1 | // tsc.ts |
RESTful API
| API 方式 | 说明 | 难度 | 例子 |
|---|---|---|---|
| 简单 API | 直接返回 JSON 数据,只对返回数据结果做约定,遵循基本的接口规范,开发随意一些 | 小 | 非常的,不具体举例 |
| RESTful API | 遵循统一的标准,非常容易量产和验收 | 大 | GithHub 开发 API 的 v3 版本 |
| GraphQL | Facebook 提出的应用层查询语言,类似 API 中间层,可以模拟 API,也可以借助 Apollo 实现一些服务器端功能 | 大 | GitHub 开放 APIdv3 版本 |
API 访问鉴权
JWT
目前流行的鉴权方式有两种:JSON Web Tokens(JWT), OAuth
1 | const jwt = require('jsonwebtoken') |
说明:
- 客户端申请令牌时,使用 jwt.sign 进行签名,并将签名结果返回客户端
- 签名体 payload 会包含用户的必要信息,以便通过 jwt.verify 进行校验时能获得该信息,作为豁免的查询依据
- 当 API 请求携带令牌时,需要先使用 jwt.verify 进行校验,成功后才能根据用户信息查询并返回数据
客户端该怎么把令牌传给服务器呢,以下是一种方法。
1 | // 检查POST的信息,URL查询参数,头部信息 |
具体逻辑如下:
- 如果 POST 请求里携带了令牌信息,则优先获取
- 其次使用查询参数里的令牌
- 最后使用头部信息里的 x-access-token
在 Koa 中,还有更好用的 koa-jwt 模块,示例如下。
1 | const jwt = require('koa-jwt') |
OAuth
- 用户打开客户端以后,客户端要求用户给予授权
- 用户用以给予客户端授权
- 客户端使用上一步获得的授权,向认证服务器申请令牌
- 认证服务器对客户端进行认证以后,确认无误,同意发放令牌
- 客户端使用令牌,向资源服务器申请获取资源
- 资源服务器确认令牌无误,同意向客户端开放资源
常用中间件
会话
- koa-session: 基于 Cookie 的简单会话实现
- koa-generic-session: Session Store 抽象层,莫表示让会话能够存储在 Redis 或 MongoDB 等自定义持久化存储中。它内置了 Memory Store,即内存存储。例如 koa-redis 是基于 Redis 存储的,koa-generic-session-mongo 是基于 MongoDB 存储的
1 | const Koa = require('koa') |
- get(sid) 根据 sid 来获取会话信息
- set(sid, sess, ttl) 通过 sid 设置会话信息,ttl 指的是会话可存活时间 ms
- destory(sid) 根据 sid 销毁会话
ETag
Etag 是前端缓存优化的重要部分.Etag 在服务器端生成后,客户端将通过 If-Match 或 If-None-Match 条件判断请求来验证资源是否被修改,其中比较常用的是 If-None-Match.如果资源没有用被修改则返回 304 状态码,如果修改则返回正常值.
1 | const conditional = require("koa-conditional-get"); |
ETag 缓存是通过 conditional-get 拦截才能生效的
koa-conditional-get 一定要放在 koa-etag 前面
一开始进入页面
200,req有字段Pragma,值为no-cache再次刷新
304,req里面有字段If-None-Match,值为 ETag 的值
验证码
例如部分网上银行有一个动态口令验证码,原理是,银行放保留一个密钥 key,同时使用动态口令生成器中的 key 与银行方保持一致,通过 OPT 等协议算法生成 6 位数字.
OTP 全程 One-time Password,也称动态口令,是根据专门的算法每隔 60s 生成的一个与时间相关的,不可预测的随机数字组合(口令),每个口令只能使用一次,每天可以产生 43200 个口令
OTP 分为两种,HOTP 和 TOTP.HOTP 是基于加法计数器和静态对称密钥的算法.TOTP 是基于时间的一次性密码算法,是支持将时间作为动态因素的,基于 HMAC 一次性密码算法的扩展算法.
OTP 实现步骤如下:
- 在一定时间范围(一般为 60s)内生成有效且复杂的字符串
- 对字符串进行散列计算
- 将结果转换为 6 位证书
- 让服务器与客户端保持时间,算法,key 同步一致
1 | // koa-opt.js |
限制访问频率
最简单好用的方法是利用 Redis 的 expire 命令.
1 | function cache_expire(k, v) { |
每次请求到来时,都需要先从缓存中查询一下,如果相应的 key 存在就不做任何处理,如果不存在就发送短信,并将 Key 保存到缓存中.
1 | // 首先检测缓存中是否有tel的key |
要点如下:
- cache_expire 可以设置 Redis 的 Key
- client.get 可以检测缓存里是否有 tel 的 Key,如果有就不做任何处理,如果没有就发送短信
还有更简单的限制访问频率的方式比如使用 ratelimiter 模块,可以通过限制用户的连接频率来防止暴力破解类的攻击
1 | var email = req.body.email; |
可以将 ratelimiter 封装成一个中间件以供使用, 而且 ratelimiter 中本身也有 koa-ratelimiter 这个现成的中间件
1 | var ratelimt = require('koa-ratelimit'); |
这里所做的就是限制了在一段时间内用户可以说尝试登陆的次数
数据库
| 术语,概念 | SQL | MongoDB |
|---|---|---|
| 数据库 | Database | Database |
| 表 | Table | Collection |
| 行 | Row | Document 或 BSON Document |
| 列 | Column | Field |
| 索引 | Index | Index |
| 表关联 | Table Joins | $lookup 或内嵌 Documents |
| 主键 | Primary Key | Primary Key, 默认为_id |
| 聚合运算 | Aggregation | Aggregation Pipeline |
MVC
视图和和控制器的职责一目了然,但视图和控制器之间,以及控制器和数据库之间如何解耦,只是就需要用到模型,模型能让业务逻辑独立且清晰。
控制器的主要工作是访问 MongoDB 数据库,完成业务逻辑编写工作,然后将数据结果返回游览器。所以,核心的数据存取工作实在 MongoDB,及经典三层架构里的数据访问层中完成的。
模型又分为领域模型和视图模型,控制器和数据库之间的是领域模型,视图和控制器之间的是视图模型。模型和数据库表之间是一一对应的,在设计模型时,除了要考虑数据库表的结构,还需要考虑 UI 渲染因素。当然,设计表结构的时候,也要考虑用户交互 UI 和用户体验 UE.
模型还有一种分类方法:充血模型和贫血模型。贫血模型把“行为”(逻辑,过程)和“状态”(数据)分离到不同的对象中。只有状态的对象就是所谓的贫血对象(Value Object, VO),而只有行为的对象就是我们常见的 N 层结构中的 Logic 层、Service 层、Manager 层。充血模型因为属于面向对象编程范畴,所以有更丰富的语义、更合理的组织和更强的可维护性。当然,贫血模型搭配 DAO(Data Access Object)和 Logic 层、Service 层、Manager 层也是不错的,是目前 JavaEE 中最常用的搭配。在 Node.js 中,以前不常用到面向对象思想,因此贫血模型就用的比较多,但随着 ES6 和 TypeScript 开始支持面向对象,未来 Node.js 应该会倾向与采用充血模型。
模型的代码
该模型只包含用户名和密码
- JavaBean
1 | public class User { |
- ES6
1 | class User { |
以上给出的简单代码只是为了说明模型具有通用意义。除了与数据库相关的领域模型外,只要是紧耦合场景,只要抽查一个模型层,都会让代码具有可读性。
使用 Sequelize 模块定义的模型代码User.js如下:
1 | module.exports = sequelize.define('user', { |
Mongoose 示例代码:
1 | module.exports = Mongoose.model('user', { |
代码组织结构

- 采用经典的 MVC 结构,包含 models, views 和 controllers 三个目录
- 包含 routes 目录,这是因为 Express 和 Koa 框架的路由都是独立的
- 包含 services 目录,这一点参考了 Java 项目,表示在控制器层和模型层之间增加了 Service 层。
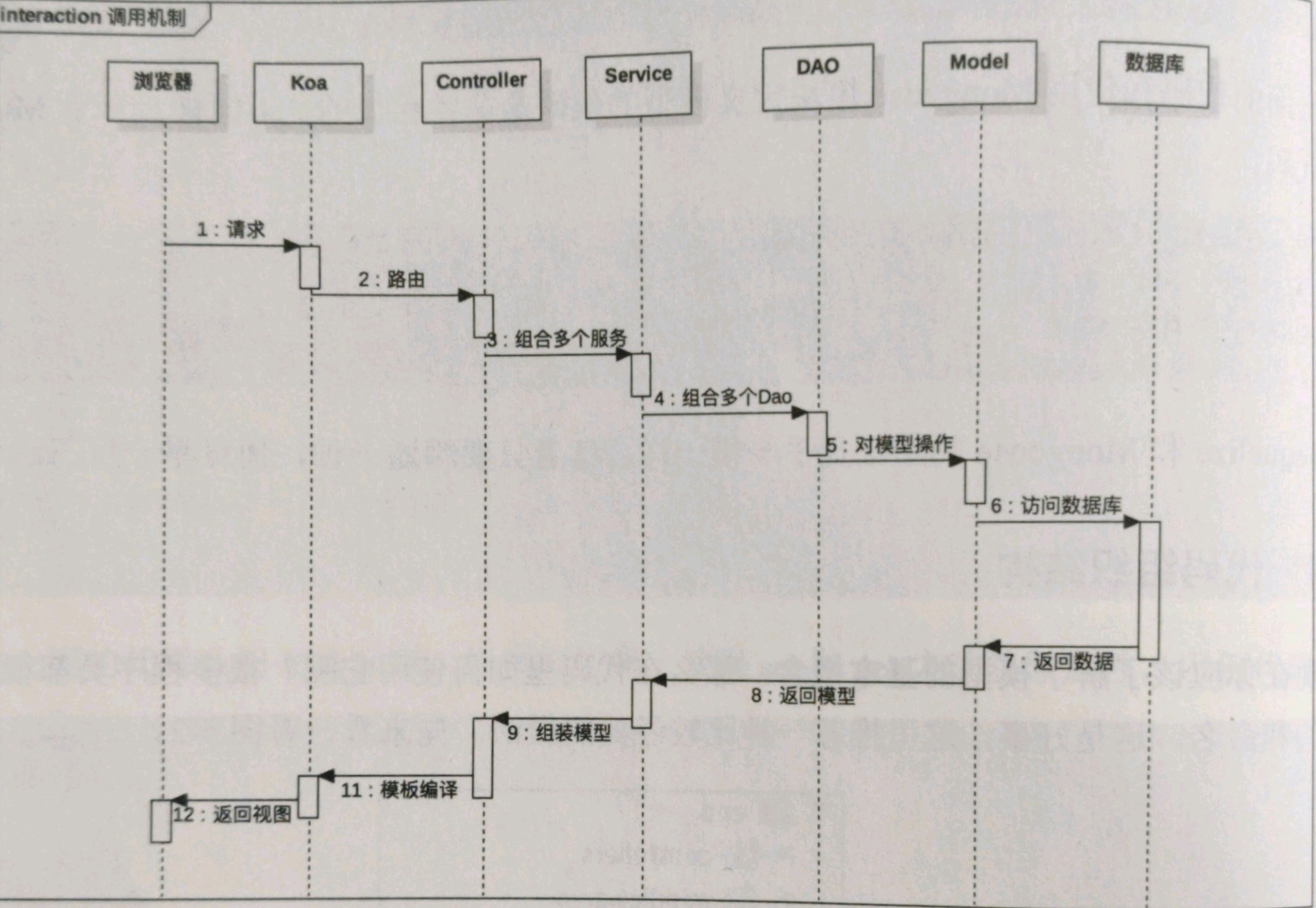
在 Java 中,大家都习惯按照图示的流程完成响应请求,在 Node.js 的世界中,也可以采取类似的方式,虽然分层以后使用起来更加复杂,但对于大型项目来说,分层时必须的。
安装与部署方式
采用复制集(Replica Set)
采用复制集是MongoDB的部署方式之一,复制集通常由三个对等的节点构成,由primary和secondary等多种角色。primary负责读/写请求,secondary负责读请求(由配置决定),secondary紧跟primary并应用写操作。如果primary失效,则集群进行“多数派”选举,选举出新的primary。复制集是MongoDB垂直扩展的最小部署单位,解决了单点故障的问题,分片集群中每个shard节点也可以使用复制集提高数据的可用性.但复制集也有缺点,只要在于集群数据的容量受限于每个节点的磁盘大小,如果数据量不断增加,对数据库进行扩容将是非常痛苦的事情.
采用分片集群(Sharding Cluster)
为了解决上述复制集的问题,需要采用分片模式,将整个集合Collection中的数据根据分片键sharding key分别存储到多个MongoDB节点上,即让每个节点持有集合的一部分数据,集群持有全部数据.这样一来,原则上分片可以支撑TB级的数据,这种方式应对高并发,超大数据量的场景时,是非常好的.
在对系统进行配置时需要注意以下几点:
建议将MongoDB部署到Linux系统上,选择较高的版本,以及合适的底层文件系统Ext4,开启合适的Swap空间.
无论是采用MMAPv1还是WiredTiger引擎,较大的内存总能带来直接的好处.
关闭数据存储文件的atime选项(表示我呢见最近被访问的时间,每次访问文件时这个时间都会被修改),可以提升文件访问效率.
调整ulimit参数.在基于网络I/O或者磁盘I/O进行操作的应用中,通常要调整这个参数,主要是为了上调系统允许大开的文件个数.
推荐以复制集位单位进行部署,简单高效,搭建分片集群是非常麻烦的,不推荐非专业的运维人士使用。
在Ubuntu上安装
更好的启动方式
1 | ! /bin/bash |
上面的shell脚本完成了如下四项内容。
- 创建目录db,pids和logs
- 如果有锁文件,则需要移除
- 创建进程id文件
- 通过mongod命令启动服务器,指定目录,IP地址,日志,进程号等。
很明显,上面的步骤不太好记,写成shell脚本也比较麻烦,更好的办法是将shell脚本嵌入npm,以二进制模块的方式进行全局安装。mh就是这样的启动模块。
1 | npm i -g mh |
mh内置了两条命令
- 当mh在当前目录下启动时,数据独立
- 当mh在用户主目录下启动时,数据共享
对于日常开发来说,推荐使用跨平台MongoDB管理客户端Robo 3T,拥有可视化界面
Mongoose基础
与MySql那样的关系型数据库相比,他显得更轻巧,灵活,非常适合在数据规模很大,事务性不强的场景下使用.同时MongoDB也是一个对象数据库,其中没有表,行等概念,也没有固定的模式和结构,所有的数据以文档的形式存储.所谓文档,就是一个关联数组式的对象,由属性组成,一个属性对应的值可能是一个数,字符串,日期,数组,甚至是一个嵌套的文档.MongoDB存储的数据格式是类似JSON的BSON格式.
Mongo 简介
Mongoose是MongoDB的一个对象模型工具.可以在Node.js异步环境下执行.同时它也是一个针对MongoDB操作的对象模型库,封装了MongoDB对文档操作的常用方法.
可以把Mongoose理解为简易版的ORM(Object-Relation-Mapping,对象关系映射),Mongoose提供了类似Schema表结构的定义,以及Hook,Plugin,Virtual,Populate等机制.
Mongoose是WordPress母公司Automattic发布的开源项目.
入门
1 | npm install --save mongoose |
1 | const Mongoose = require("mongoose") |
说明:
user是MongoDB里的用户名
pass是MongoDB里该用户对应的密码
ip是MongoDB服务器可以访问的ip地址,如127.0.0.1
port是MongoDB服务器可以访问的端口,默认是27017
连接MySQL和MongoDB本质上都是TCP连接,所以配置也大同小异
测试连接
1 | const Mongoose = require("mongoose") |
最小示例
1 | // 最小示例 |
上述有3个核心步骤
- 定义模型
- 通过关键字new实例化Cat模型,创建kitty对象
- 执行kitty.save方法,将模型数据保存到数据库
总结下:首先约定Schema,即定义模型时指定字段和字段类型,避免出现乱用scheme-free的问题;然后,对实例化模型创建的对象进行操作,完成常见的增删改查功能。定义模型即定义对象,对对象进行操作即对数据库进行操作。
Hello Mongoose
连接数据库的实际代码db/mini/connect.js
1 | const Mongoose = require('mongoose') |
一般在项目里面,所有模型都共用一个数据库连接信息,把连接数据库的代码抽取到connect.js中,然后在引用入口引用,这样整个应用里就只存在一个数据库连接了
定义模型db/mini/user.js
1 | const Mongoose = require('mongoose') |
这是MVC中做常见的代码,没有连接信息,也没有其他额外不相干的的代码,一般看user.js文件就能理解它在数据库里对应的表结构,以及字段类型,约束等信息。
实际测试代码db/mini/test.js
1 | require('./connect') |
核心步骤:
- 引入数据库连接,保证MongoDB已经连接成功
- 引入模型定义文件,完成文档(表)结构的定义
- 实例化User模型,创建user实体
- 通过user实体对数据库进行操作,完成用户注册
核心概念
对象关系映射
面向对象是软件工程基本原则(耦合、聚合、封装)的基础上发展起来的,而关系型数据库则是从数学理论中发展而来的,两套理论存在显著区别。为了解决二者不匹配的问题,对象关系映射技术应运而生。
对象关系映射(Object Relational Mappling,简称ORM)是一种程序设计技术,用于实现面向对象编程语言里不同类型系统数据之间的转换。从效果上说,它实际上创建了一个可以在编程语言里使用的“虚拟对象数据库”。
几乎所有程序里都存在对象和关系型数据库,在业务逻辑层和用户界面层中,推荐使用面向对象的写法。当对象信息发生变化的时候,把对象信息保存到关系型数据库中。
ORM提供了概念性的、易于理解的模型化数据的方法。对于MongoDB这种基于文档的非关系型数据库来说,与ORM对应的概念是ODM(Object-Document Mapper),即对象文档映射。
ORM是关系型数据库的对象关系映射工具,ODM是MongoDB特有的对象文档映射工具,而Mongoose是ORM工具。
Schema
Schema是一种以文件形式存储的数据库模型骨架,并不直接连接数据库,也就是说他不具备对数据库操作的能力,仅仅负责定义数据库模型在程序中的映射配置。可以说Schema是数据属性模型(传统意义上的表结构),或者“集合”的模型骨架。Schema是对文档(表)结构的定义。
Schema的基本属性类型有字符串、日期、数值、布尔值、null、数组、内嵌文档等,当然它还有更丰富的字段进行校验约束功能。
模型
模型是由Schema构造而来的,除了包含Schema定义的数据库骨架以外,还包含了对数据库操作的行为,可以把它理解成操作Schema属性与行为的类。
1 | const UserModel = Mongoose.model('User', UserSchema); |
User是模型名称,对应的MongoDB中的概念就是数据库中的集合名称,默认会转成复数,即users。当我们对数据库添加数据时秒如果users已经存在,则将数据保存到users集合中即可;如果users不存在,则需要创建users集合,然后保存数据。
在后面的内容中,我们会使用模型来执行增删改查操作,所以一定要熟悉它的创建格式。如果想对某个Collect进行操作,就交给模型。创建一个模型,需要指定集合名称及集合的Schema结构对象。
实体
实体是由模型创建的,它使用save方法来保存数据。模型和实体都能执行影响数据库的操作,但前者更具操作性。
1 | const user = new User({ |
创建成功之后,Schema的属性就变成了模型和实体的公共属性。
总结:Schema是骨架,模型是根据Schema创建的模板类,也就是Schema和模型是对数据库表的定义,而实体是模型实例化后的对象,是真正具有数据库操作能力的对象。
所以,我们会把数据库表的定义部分(Schema + 模型)和实体分开,此时定义是不变的。而通过实体对数据库进行操作时,数据是会产生变化的。所以在进行MVC分层的时候,模型中实际上放的是定义部分,而Contorller层里使用的是实体部分。
增删改查
CRUD为Create(增加),Retrieve(读取),Update(更新)和Delete(删除)几个单词的首字母组合.Mongoose提供了如下的Crud方法.
- 增加: save
- 读取: find, findOne
- 更新: update, findByIdAndUpdate, findOneAndUpdate
- 删除: remove
增加
1 | const user = new User({ |
save还有一个别名,create
读取
执行读取操作时有两个API: find 和 findOne.其中,find表示根据条件查询并返回数组; findOne表示根据条件查询并返回一个数据对象.
find
find表示根据条件查询,返回的是数组.
1 | User.find({}, (err, docs) => { |
findOne
findOne表示根据条件查询,返回的是一个数据对象
1 | User.findOne({}, (err, docs) => { |
其实还有findOneAndUpdate,findAndModify,findByIdAndUpdate,findOneAndRemove,findByIdAndRemove等辅助方法.
更新,除了update方法,更新操作还可以通过很多其他方法来完成.比如findByIdAndUpdate,findOneAndUpdate
更新
update
1
2
3
4
5
6
7
8
9
10
11
12/**
Parameters
conditions «Object»
doc «Object»
[options] «Object» optional see Query.prototype.setOptions()
[callback] «Function»
*/
//多条
User.update({ username: 'wzy' }, { password: 'basketball' }, { multi: true }, function (err, raw) { // multi多匹配
if (err) return handleError(err);
console.log('The raw response from Mongo was ', raw);
})findByIdAndUpdate
1
2
3
4
5
6
7
8
9
10
11
12
13
14/**
Parameters
id «Object|Number|String» value of _id to query by
[update] «Object»
[options] «Object» optional see Query.prototype.setOptions()
[options.lean] «Object» if truthy, mongoose will return the document as a plain JavaScript object rather than a mongoose document. See Query.lean().
[callback] «Function»
*/
User.findByIdAndUpdate('5ec62cbc797f681cdcd257e2', {
username: 'wjj'
}, function (err, user) {
if (err) return handleError(err);
console.log('The raw response from Mongo was ', raw);
})findOneAndUpdate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/**
Parameters
[conditions] «Object»
[update] «Object»
[options] «Object» optional see Query.prototype.setOptions()
[options.lean] «Object» if truthy, mongoose will return the document as a plain JavaScript object rather than a mongoose document. See Query.lean().
[callback] «Function»
*/
User.findOneAndUpdate({
username: 'wjj2'
}, {
password: 'wjj2'
}, function (err, user) {
if (err) console.log('find error:' + err)
console.log('The raw response from Mongo was ', raw);
})
删除
1 | User.remove({username: 'wzy_copy'}, (err, doc) => { |
测试
1 | const test = require('ava') |
1 | npm test |
在测试代码里,我们不需要真的调用数据库的具体方法,一般使用Sinon这样的库来模拟操作即可.比如,给UserModel增加一个save方法.
1 | const sinon = require('sinon') |
调试模式
调试模式是Mongoose提供的一个非常实用的功能,用于查看Mongoose模块对MongoDB操作的日志.一般我们在进行开发时会打开此功能,以便更好地优化对MongoDB的操作
1 | // 核心代码,开启调试模式 |
Schema的类型
1 | node mongooseTest.js |
下面时更完整的示例,以及如何在项目中更好的使用
1 |
|
Mongoose 进阶
模型扩展
模型有充血贫血之分,充血模型简单的理解就是模型自身带有行为.在MVC模式里,模型层和业务层之间的职业要做好区分,适当地将业务行为下沉到模型层,代码会更加清晰,可维护性也更高.
一般情况下,我们对业务进行如下的分层处理.
Service层 (多模型操作) => DAO层(单一模型操作) => 模型层(模型定义)
我们需要在DAO层封装很多单一模型的数据库操作方法.但是,如果业务非常复杂,比如有一个超级查询方法,还有各种具体业务的定义方法,难道要将这些全部写在DAO层嘛?
事实上,DAO层只提供暴露给Service层的方法,而具有一定业务约定的方法是要封装到模型层的.如果把DAO层的很多底层方法下沉到模型层,就可以让这两个分层的职责更加清晰.所以,我们需要利用Mongoose的模型扩展来重新定义分层,扩展后的分层结构如下.
Service层(多模型操作) => DAO层(单一模型操作) => 模型层(模型定义+扩展方法)
Mongoose提供的模型扩展方法有两种,如下:
statics: 类上扩展
methods: 对象上扩展
类上扩展
假设有这样一个需求,根据用户名查找用户.那么这个查找用户的行为到底是放到类的静态方法上,还是放到示例方法上呢
对于这种不属于某个用户的具体行为,在类上扩展会更好
1 | UserSchema.statics.find_by_username = function(username, cb) { |
by_username是User模型的静态方法,调用方法如下
1 | const User = mongoose.model('User',UserScheme) |
对象上扩展
如果是用户的具体行为,在对象上扩展会更具有可读性.在对象上扩展行为时,需根据当前模型已有的属性进行扩展,再结合查询进行晚上,这样实现的功能会非常强大.比如判断某个用户是否存在,就是典型的用户的具体行为.
1 | UserSchema.methods.is_exist = function(cb) { |
需要创建也User对象.才能调用is_exist方法
1 | const user = new User |