rust 所有权
总结
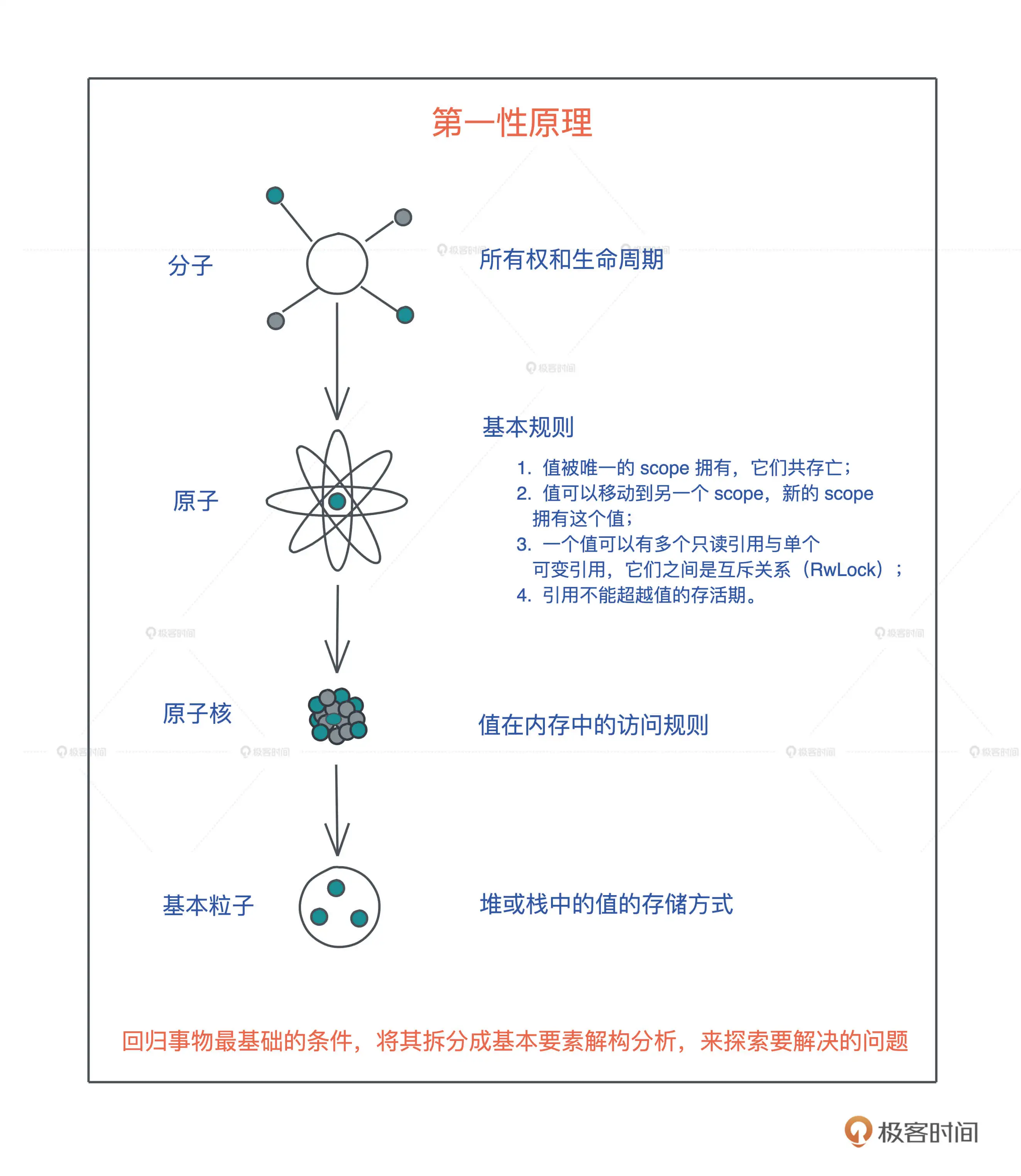
- 所有权:一个值只能被一个变量所拥有,且同一时刻只能有一个所有者,当所有者离开作用域,其拥有的值被丢弃,内存得到释放。
- Move 语义:赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
- Copy 语义:如果值实现了 Copy trait,那么赋值或传参会使用 Copy 语义,相应的值会被按位拷贝(浅拷贝),产生新的值。
规则:
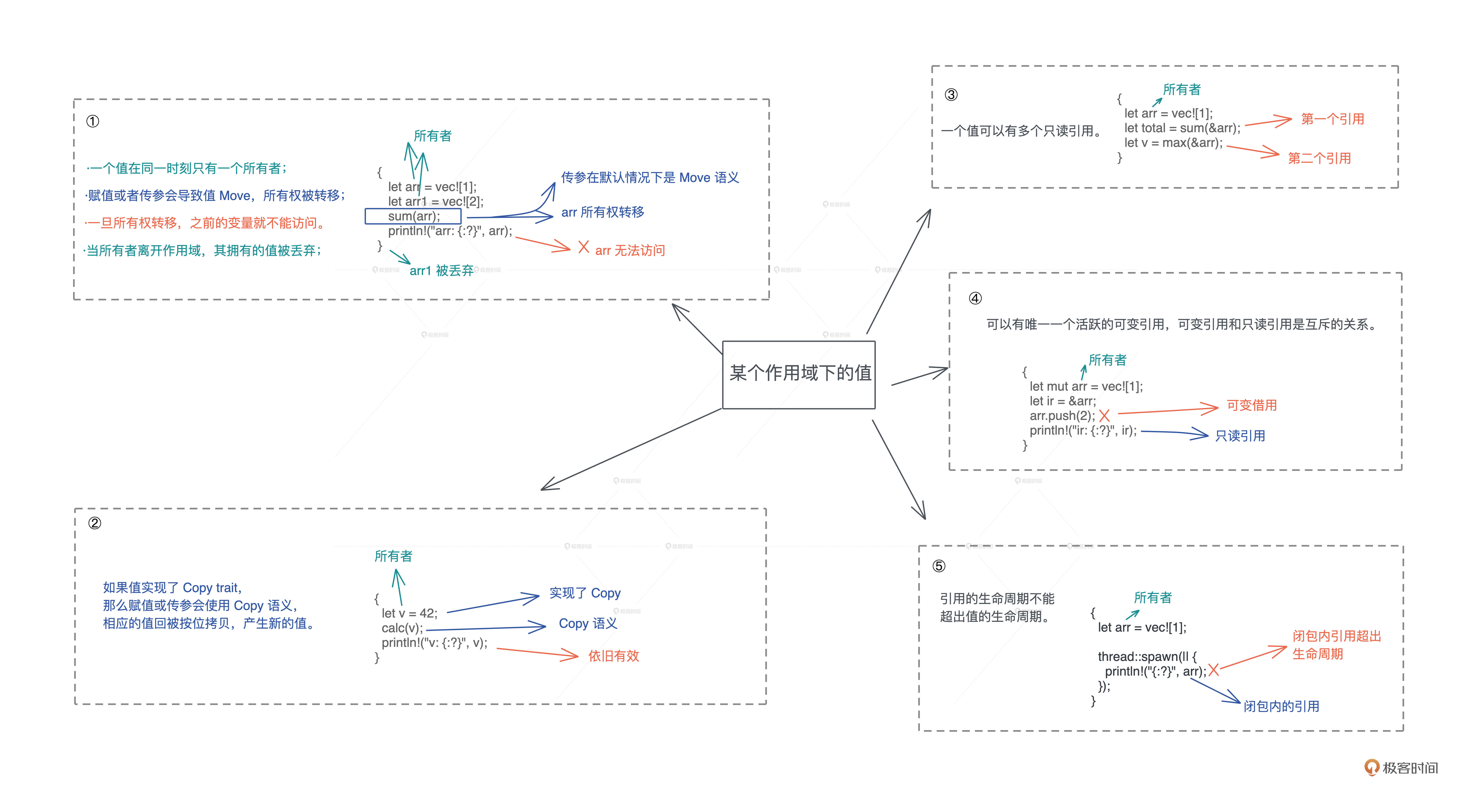
- 一个值在同一时刻只有一个所有者。当所有者离开作用域,其拥有的值会被丢弃。赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
- 如果值实现了 Copy trait,那么赋值或传参会使用 Copy 语义,相应的值会被按位拷贝,产生新的值。
- 一个值可以有多个只读引用。
- 一个值可以有唯一一个活跃的可变引用。可变引用(写)和只读引用(读)是互斥的关系,就像并发下数据的读写互斥那样。
- 引用的生命周期不能超出值的生命周期。
变量在函数调用时发生了什么
1 | fn main() { |
动态数组因为大小在编译期无法确定,所以放在堆上,并且在栈上有一个包含了长度和容量的胖指针指向堆上的内存。
对于堆内存多次引用的问题,我们先来看大多数语言的方案:
- C/C++ 要求开发者手工处理
- Java 等语言使用追踪式 GC
- ObjC/Swift 使用自动引用计数(ARC)
Rust 的解决思路
- 一个值只能被一个变量所拥有,这个变量被称为所有者(Each value in Rust has a variable that’s called its owner)。
- 一个值同一时刻只能有一个所有者(There can only be one owner at a time),也就是说不能有两个变量拥有相同的值。所以对应刚才说的变量赋值、参数传递、函数返回等行为,旧的所有者会把值的所有权转移给新的所有者,以便保证单一所有者的约束。
- 当所有者离开作用域,其拥有的值被丢弃(When the owner goes out of scope, the value will be dropped),内存得到释放。
在这三条所有权规则的约束下,我们看开头的引用问题是如何解决的:
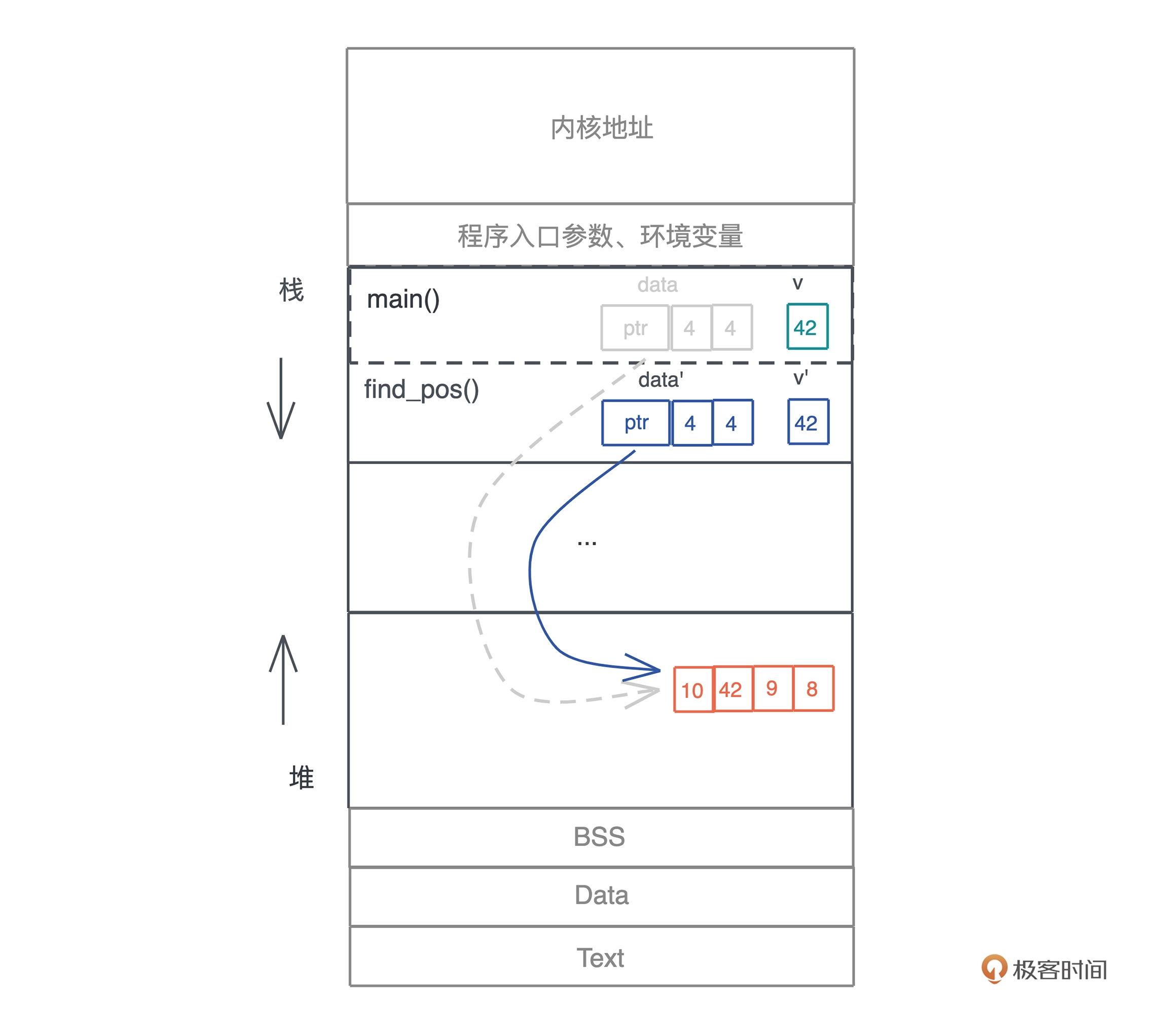
Move 语义
原先 main() 函数中的 data,被移动到 find_pos() 后,就失效了,编译器会保证 main() 函数随后的代码无法访问这个变量,这样,就确保了堆上的内存依旧只有唯一的引用。这也就是 Move 语义
如果要同时访问的话就使用 data.clone() 把 data 复制一份出来
所有权规则,解决了谁真正拥有数据的生杀大权问题,让堆上数据的多重引用不复存在,这是它最大的优势。
Copy 语义和 Copy trait
符合 Copy 语义的类型,在你赋值或者传参时,值会自动按位拷贝。
换句话说,当你要移动一个值,如果值的类型实现了 Copy trait,就会自动使用 Copy 语义进行拷贝,否则使用 Move 语义进行移动。
- 原生类型,包括函数、不可变引用和裸指针实现了 Copy;
- 数组和元组,如果其内部的数据结构实现了 Copy,那么它们也实现了 Copy;
- 可变引用没有实现 Copy;
- 非固定大小的数据结构,没有实现 Copy。
实现了 Copy trait 的数据结构
1 |
|
Borrow 语义
Borrow 语义允许一个值的所有权,在不发生转移的情况下,被其它上下文使用。
语法(& 或者 &mut)
在 Rust 下,所有的引用都只是借用了“临时使用权”,它并不破坏值的单一所有权约束。因此默认情况下,Rust 的借用都是只读的。
只读借用 / 引用
本质上,引用是一个受控的指针,指向某个特定的类型。在学习其他语言的时候,你会注意到函数传参有两种方式:传值(pass-by-value)和传引用(pass-by-reference)。
但 Rust 没有传引用的概念,Rust 所有的参数传递都是传值,不管是 Copy 还是 Move。所以在 Rust 中,你必须显式地把某个数据的引用,传给另一个函数。
Rust 的引用实现了 Copy trait,所以按照 Copy 语义,这个引用会被复制一份交给要调用的函数。对这个函数来说,它并不拥有数据本身,数据只是临时借给它使用,所有权还在原来的拥有者那里。
在 Rust 里,引用是一等公民,和其他数据类型地位相等。
只读引用实现了 Copy trait,也就意味着引用的赋值、传参都会产生新的浅拷贝。
借用的生命周期及其约束
值的引用也要有约束,这个约束是:借用不能超过(outlive)值的生存期。
生命周期更长的 main() 函数变量 r ,引用了生命周期更短的 local_ref() 函数里的局部变量,这违背了有关引用的约束
1
2
3
4
5
6
7
8
9fn main() {
let r = local_ref();
println!("r: {:p}", r);
}
fn local_ref<'a>() -> &'a i32 {
let a = 42;
&a
}在堆内存中,使用栈内存的引用
1
2
3
4
5
6fn main() {
let mut data: Vec<&u32> = Vec::new();
let v = 42;
data.push(&v);
println!("data: {:?}", data);
}堆内存中使用了生命周期更短的局部变量
1
2
3
4
5
6
7
8
9
10
11
12
fn main() {
let mut data: Vec<&u32> = Vec::new();
push_local_ref(&mut data);
println!("data: {:?}", data);
}
fn push_local_ref(data: &mut Vec<&u32>) {
let v = 42;
data.push(&v);
}
这三段代码看似错综复杂,但如果抓住了一个核心要素“在一个作用域下,同一时刻,一个值只能有一个所有者”,你会发现,其实很简单。
堆变量的生命周期不具备任意长短的灵活性,因为堆上内存的生死存亡,跟栈上的所有者牢牢绑定。而栈上内存的生命周期,又跟栈的生命周期相关,所以我们核心只需要关心调用栈的生命周期。
可变借用 / 引用
错误示范
1. 多个可变引用
1 | fn main() { |
这段代码在遍历可变数组 data 的过程中,还往 data 里添加新的数据,这是很危险的动作,因为它破坏了循环的不变性(loop invariant),容易导致死循环甚至系统崩溃。
所以,在同一个作用域下有多个可变引用,是不安全的。
2. 同时有一个可变引用和若干个只读引用
1 | fn main() { |
不可变数组 data1 引用了可变数组 data 中的一个元素,这是个只读引用。后续我们往 data 中添加了 100 个元素,在调用 data.push() 时,我们访问了 data 的可变引用。
仔细推敲,就会发现这里有内存不安全的潜在操作:如果继续添加元素,堆上的数据预留的空间不够了,就会重新分配一片足够大的内存,把之前的值拷过来,然后释放旧的内存。这样就会让 data1 中保存的 &data[0] 引用失效,导致内存安全问题。
Rust 的限制
多个可变引用共存、可变引用和只读引用共存这两种问题,通过 GC 等自动内存管理方案可以避免第二种,但是第一个问题 GC 也无济于事。
所以为了保证内存安全,Rust 对可变引用的使用也做了严格的约束:
- 在一个作用域内,仅允许一个活跃的可变引用。所谓活跃,就是真正被使用来修改数据的可变引用,如果只是定义了,却没有使用或者当作只读引用使用,不算活跃。
- 在一个作用域内,活跃的可变引用(写)和只读引用(读)是互斥的,不能同时存在。
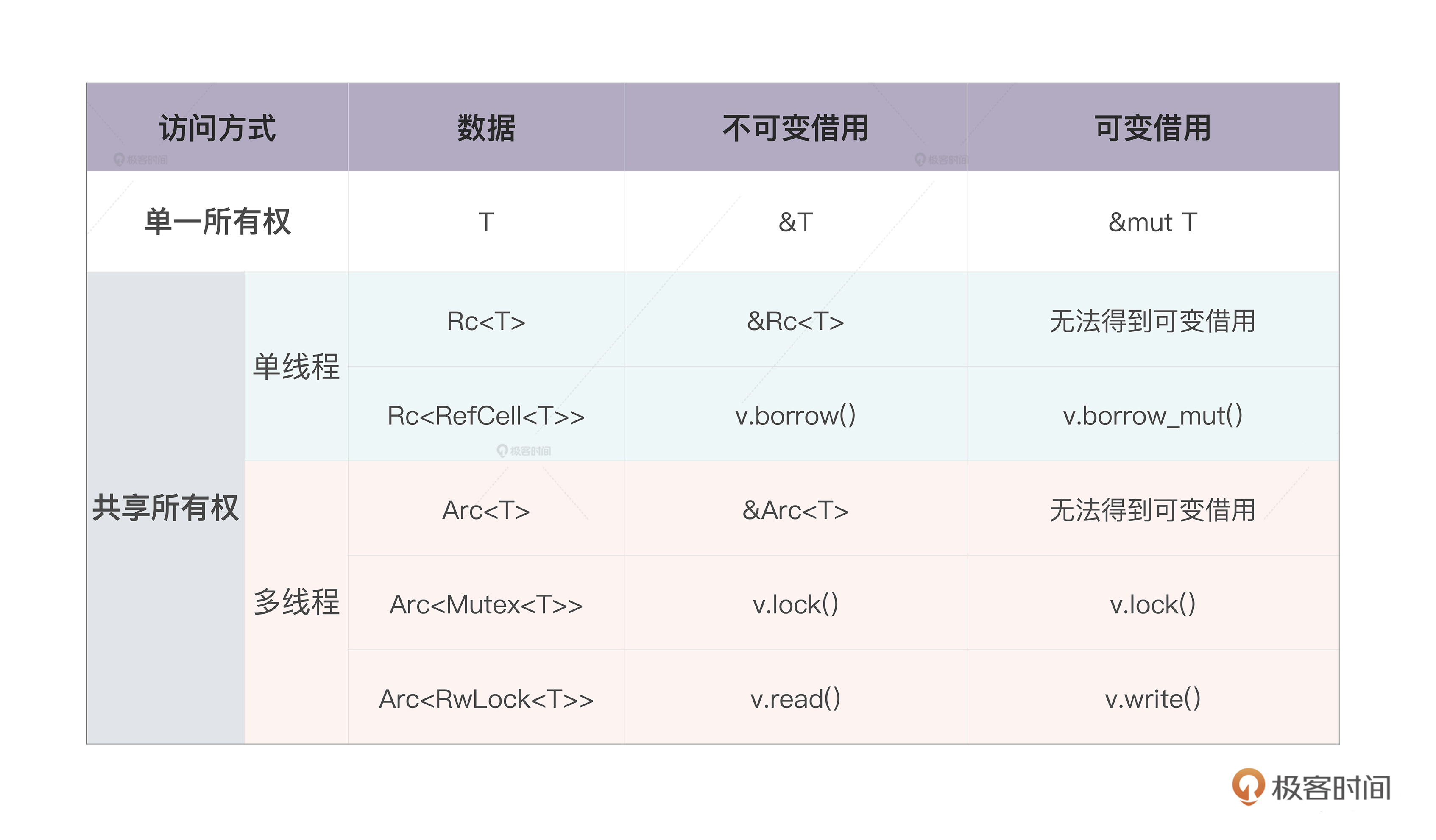
共享所有权
Rc(Reference counter) 和 Arc(Atomic reference counter)。
Rc
我们先看 Rc。对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者。Rc 会把对应的数据结构创建在堆上,我们在第二讲谈到过,堆是唯一可以让动态创建的数据被到处使用的内存。
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存。
1 | use std::rc::Rc; |
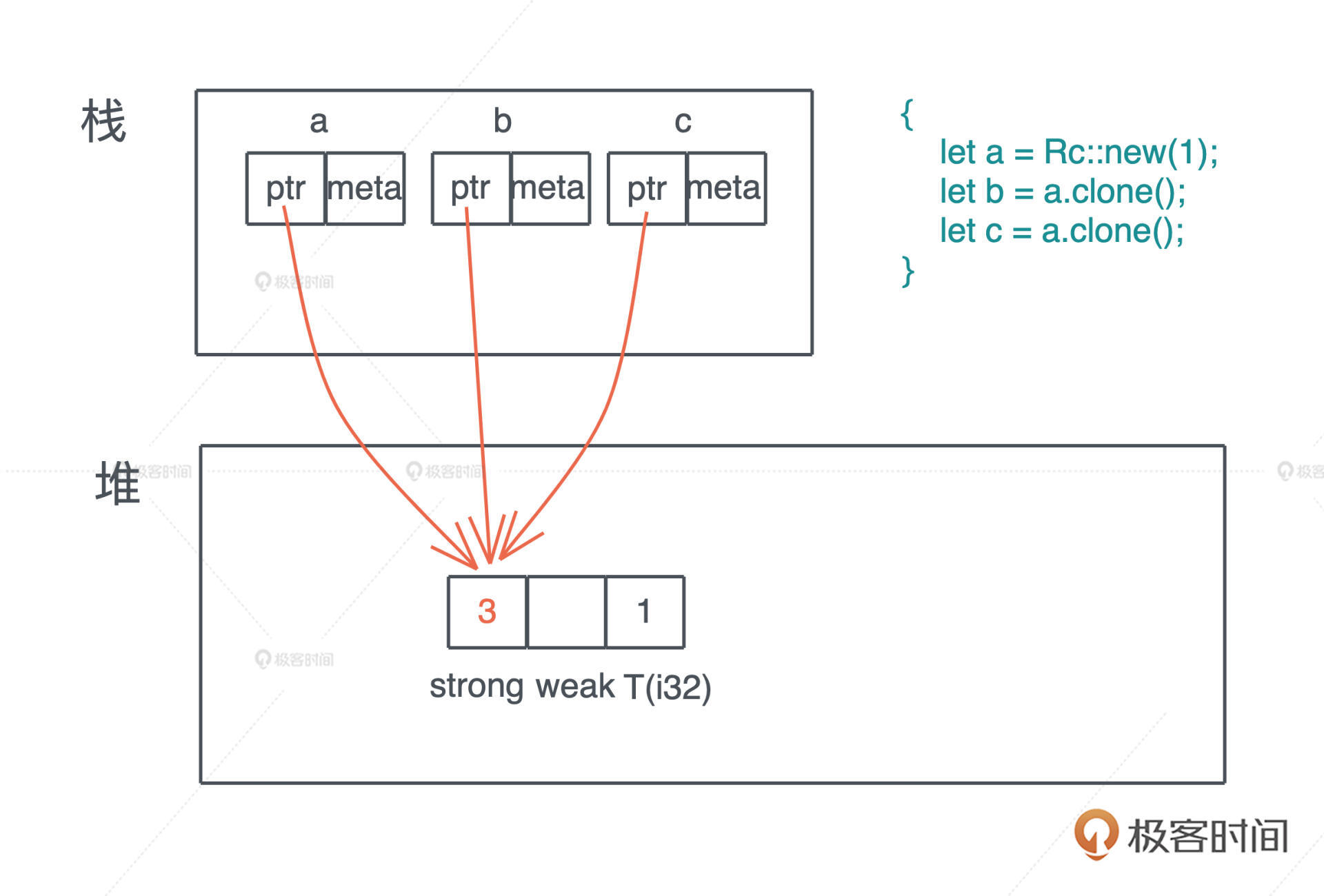
上面的代码我们创建了三个 Rc,分别是 a、b 和 c。它们共同指向堆上相同的数据,也就是说,堆上的数据有了三个共享的所有者。在这段代码结束时,c 先 drop,引用计数变成 2,然后 b drop、a drop,引用计数归零,堆上内存被释放。
为什么我们生成了对同一块内存的多个所有者,但是,编译器不抱怨所有权冲突呢?
仔细看这段代码:首先 a 是 Rc::new(1) 的所有者,这毋庸置疑;然后 b 和 c 都调用了 a.clone(),分别得到了一个新的 Rc,所以从编译器的角度,abc 都各自拥有一个 Rc。如果文字你觉得稍微有点绕,看看 Rc 的 clone() 函数的实现,就很清楚了,clone 源代码
1 |
|
Rc 的 clone() 正如我们刚才说的,不复制实际的数据,只是一个引用计数的增加。
Rc 是怎么产生在堆上的?并且为什么这段堆内存不受栈内存生命周期的控制呢?
Box::leak() 机制
在所有权模型下,堆内存的生命周期,和创建它的栈内存的生命周期保持一致。所以 Rc 的实现似乎与此格格不入。的确,如果完全按照上一讲的单一所有权模型,Rust 是无法处理 Rc 这样的引用计数的。Rust 必须提供一种机制,让代码可以像 C/C++ 那样,创建不受栈内存控制的堆内存,从而绕过编译时的所有权规则。Rust 提供的方式是 Box::leak()。
Box 是 Rust 下的智能指针,它可以强制把任何数据结构创建在堆上,然后在栈上放一个指针指向这个数据结构,但此时堆内存的生命周期仍然是受控的,跟栈上的指针一致。我们后续讲到智能指针时会详细介绍 Box。
Box::leak(),顾名思义,它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查。
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
- 静态检查,靠编译器保证代码符合所有权规则;
- 动态检查,通过 Box::leak 让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放。
RefCell
Rc 是一个只读的引用计数器,你无法拿到 Rc 结构内部数据的可变引用,来修改这个数据。这可怎么办?这里,我们需要使用 RefCell。
和 Rc 类似,RefCell 也绕过了 Rust 编译器的静态检查,允许我们在运行时,对某个只读数据进行可变借用。这就涉及 Rust 另一个比较独特且有点难懂的概念:内部可变性(interior mutability)。
内部可变性
有内部可变性,自然能联想到外部可变性,所以我们先看这个更简单的定义,对比着学。
当我们用 let mut 显式地声明一个可变的值,或者,用 &mut 声明一个可变引用时,编译器可以在编译时进行严格地检查,保证只有可变的值或者可变的引用,才能修改值内部的数据,这被称作外部可变性(exterior mutability),外部可变性通过 mut 关键字声明。
然而,这样不够灵活,有时候我们希望能够绕开这个编译时的检查,对并未声明成 mut 的值或者引用,也想进行修改。也就是说,在编译器的眼里,值是只读的,但是在运行时,这个值可以得到可变借用,从而修改内部的数据,这就是 RefCell 的用武之地。
1 | use std::cell::RefCell; |
在这个例子里,data 是一个 RefCell,其初始值为 1。可以看到,我们并未将 data 声明为可变变量。之后我们可以通过使用 RefCell 的 borrow_mut() 方法,来获得一个可变的内部引用,然后对它做加 1 的操作。最后,我们可以通过 RefCell 的 borrow() 方法,获得一个不可变的内部引用,因为加了 1,此时它的值为 2。
你也许奇怪,这里为什么要把获取和操作可变借用的两句代码,用花括号分装到一个作用域下?因为根据所有权规则,在同一个作用域下,我们不能同时有活跃的可变借用和不可变借用。通过这对花括号,我们明确地缩小了可变借用的生命周期,不至于和后续的不可变借用冲突。
Arc 和 Mutex/RwLock
开头提到的多个线程访问同一块内存的问题,是否也可以使用 Rc 来处理呢?不行。因为 Rc 为了性能,使用的不是线程安全的引用计数器。因此,我们需要另一个引用计数的智能指针:Arc,它实现了线程安全的引用计数器。
Arc 内部的引用计数使用了 Atomic Usize ,而非普通的 usize。从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全。
Rust 实现两套不同的引用计数数据结构,完全是为了性能考虑,从这里我们也可以感受到 Rust 对性能的极致渴求。如果不用跨线程访问,可以用效率非常高的 Rc;如果要跨线程访问,那么必须用 Arc。
同样的,RefCell 也不是线程安全的,如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock。
- Mutex 是互斥量,获得互斥量的线程对数据独占访问
- RwLock 是读写锁,获得写锁的线程对数据独占访问,但当没有写锁的时候,允许有多个读锁。